This article as well as most of my web scraping articles are heavily inspired based on John Watson Rooney’s video on the subject.
Overview
Any public website can be scraped, the only question is how and is the effort worth it?
Some websites are relatively simple, take for instance this very site. On the other hand, take Google Maps, the public facing API of maps is intentionally convoluted and while I believe it is theoretically possible scrape it, the more programmatic approach is to just sign up for a Google Maps API key.
How Websites Work
Whenever you connect to a server, you send a request to that server to get the information (the webpage) assigned to the URL. In simple static websites, that might just be a single GET request that gets the HTML content of the page. Then you can use an HTML parser such as BeautifulSoup4 in Python to parse the content. Simple.
However most websites, at least most websites worth scraping, are not as simple. They will often have client side javascript that have one or more APIs calls that pull from one or more databases, loading all said information asynchronously. In that case simply sending a GET request for the HTML page is not going to be sufficient, all you will get is a template with the key data missing.
Public APIs
Although you may not realize it, when you open a website like realtor.com multiple API requests will fire which obtain information not included on the HTML page source, such as active property listings.
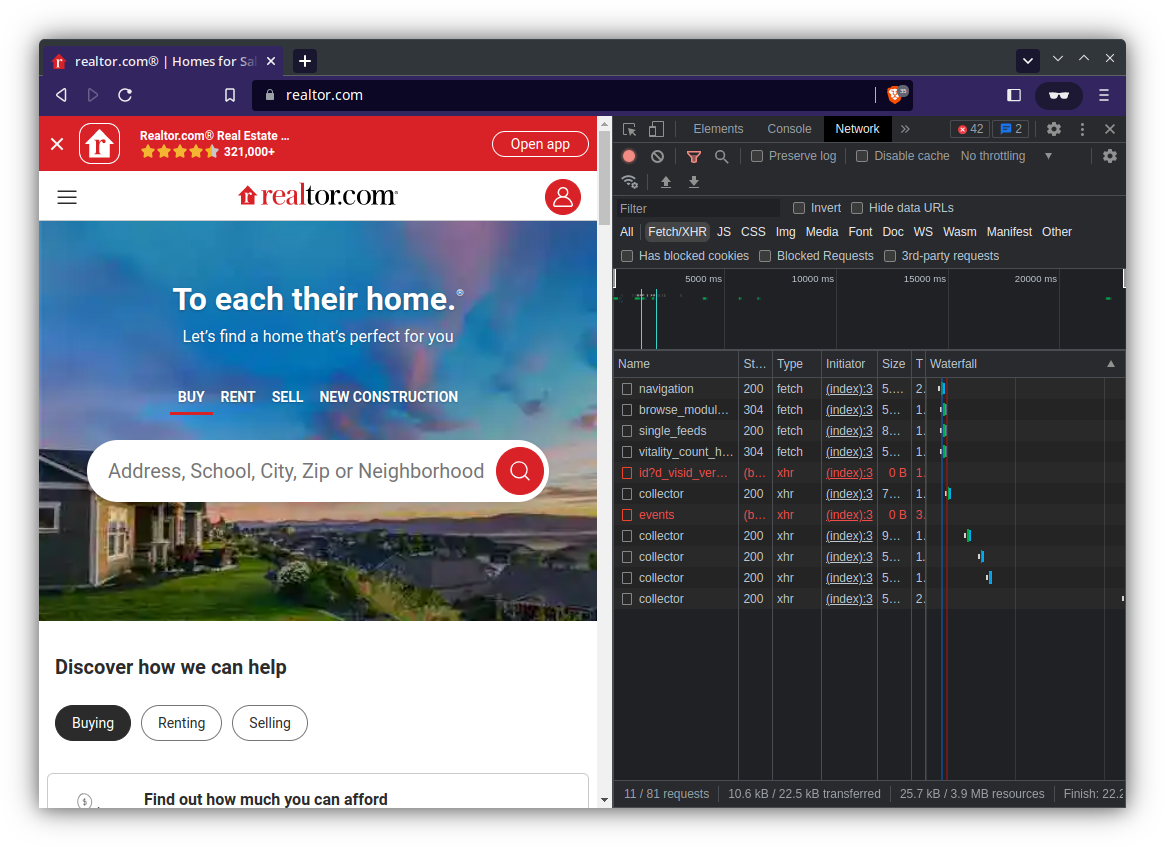
For the purpose of this article I will be showcasing a simpler website, if you are interested in see how to scrape realtor.com, see this article.
Reverse Engineering Public APIs
I’ll be extracting all the symbol tickers on the NYSE (New York Stock Exchange) from NYSE Symbols Table.
Identifying the API
To start off with, we need to identify the API. The best way is to use a Chromium based browser (Chrome, Brave, etc.) such that we can take advantage of the advanced developer tools.
- Open nyse.com/listings_directory/stock
- Right click on the page and click
Inspect - This opens up right side menu with the developer tools
- In the side menu, open the
Networktab - Under the filter box, select
Fetch/XHR- This will show just the API requests
- Click through the table and observe which network requests are being made
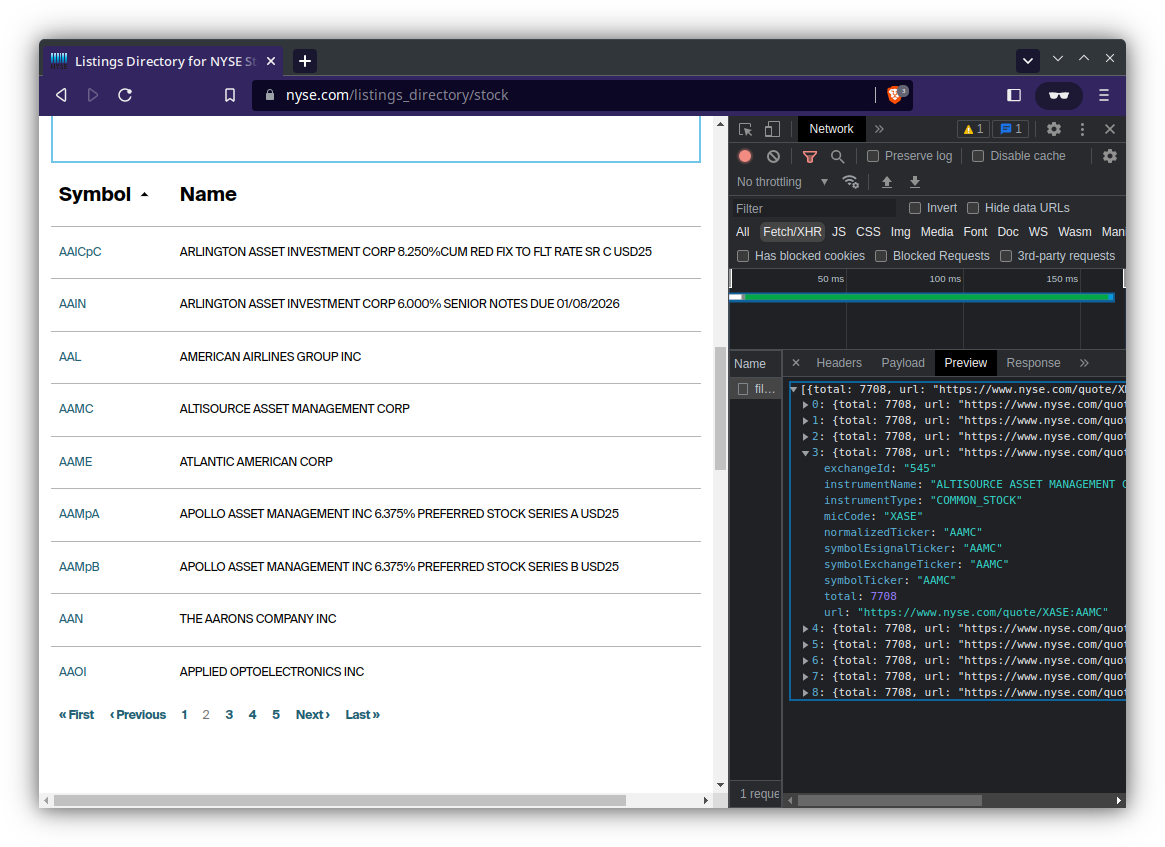
You can see that request named filter is the one that is fetching the data.
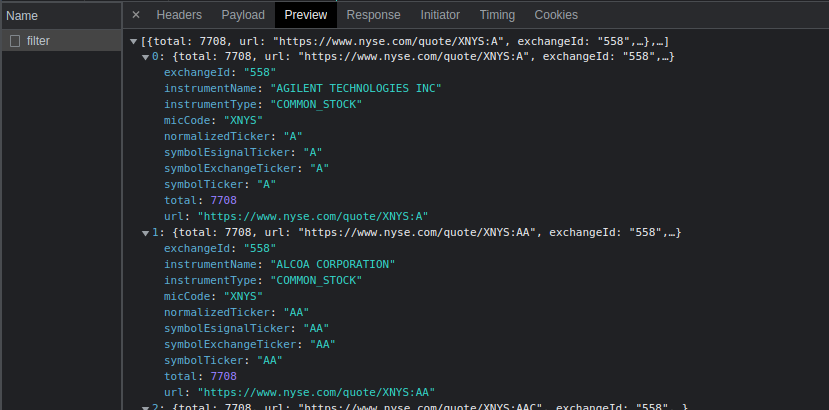
Understanding the API
Now that we’ve identified the API, the trick is to understand (at least partially) how it works. This is where an API debugger comes in.
Although we could manually try to tinker with the API request, using an API debugger makes like significantly easier. My go-to debugger is Insomnia which is a free and open source application.
So let’s get started…
- In the DEV tools, right click the
filterrequest, hover overcopy, then clickcopy as cURL
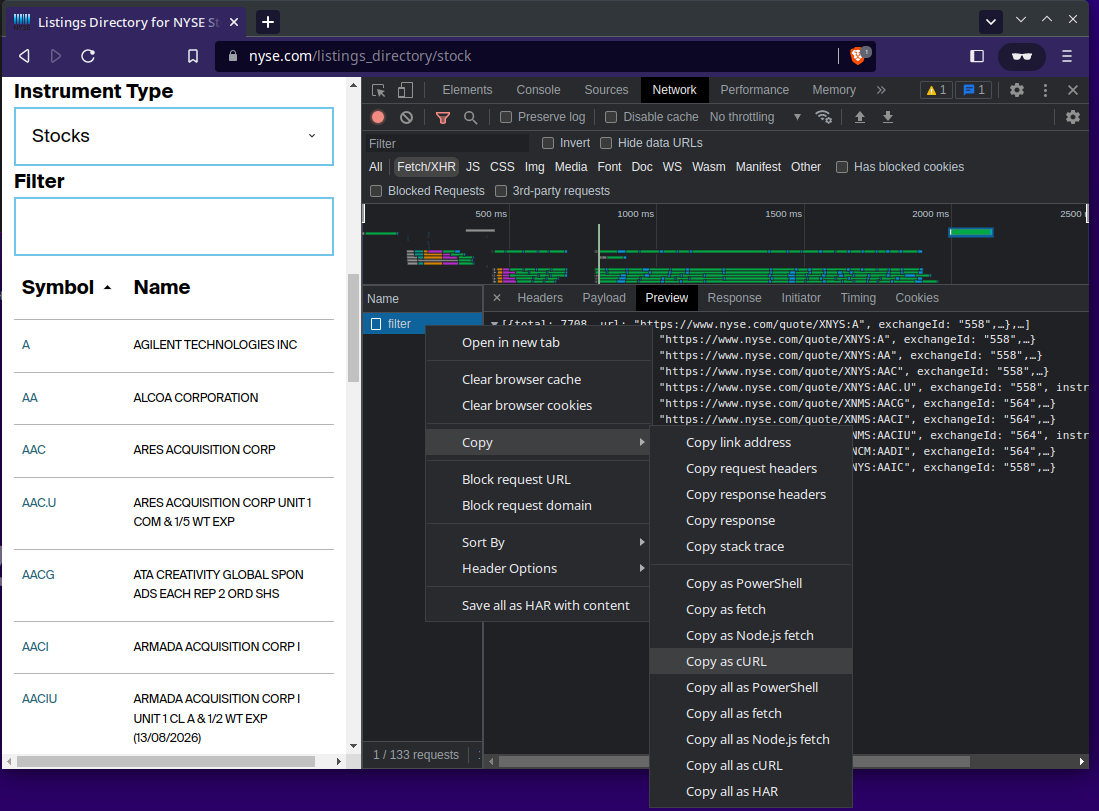
- Open Insomnia and paste the
cURLyou just copied- Insomnia will automatically parse the
cURLrequest
- Insomnia will automatically parse the
- Click
Sendin Insomnia- You should see a green
200 OKand some stock tickers in the preview.
- You should see a green
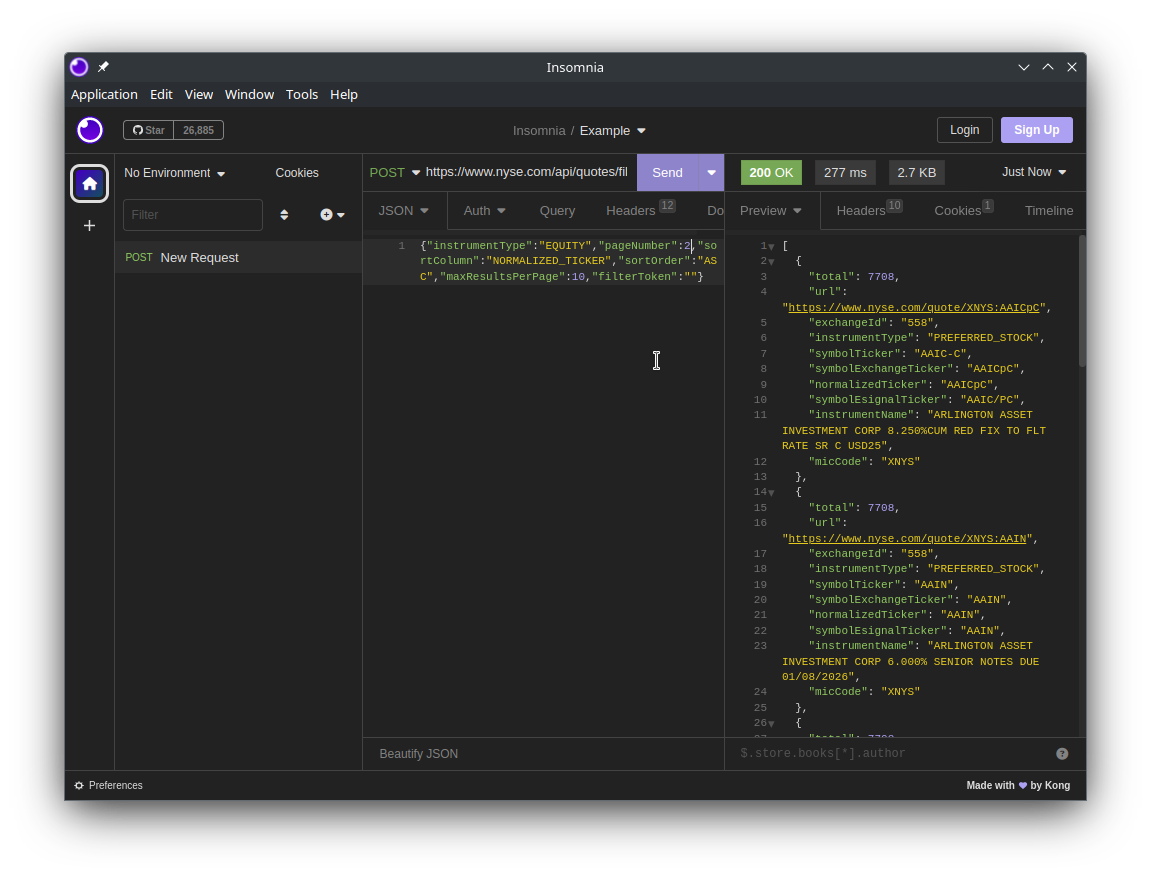
Let’s look at the request JSON…
|
|
After some tinkers, we can see that changing pageNumber will let use cycle through all the symbol tickers. So we can iterate through pageNumber then parse the response JSON to get all the tickers. However we still need to determine what happens when we hit the end.
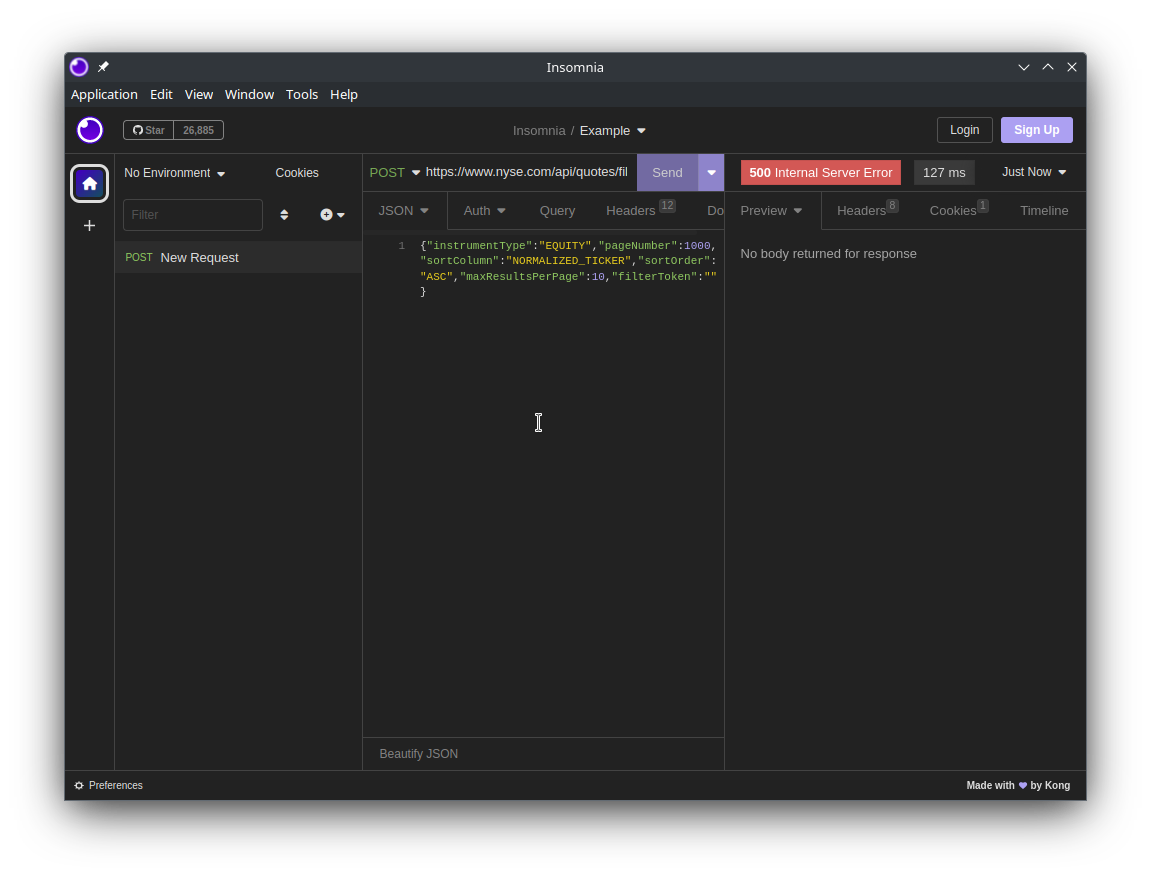
If we try "pageNumber":1000, we will get a 500 Internal Server Error. This is a good thing, we now have a defined start point ("pageNumber":1) and the end point (status code 500).
Generating Code
One of the perks of Insomnia is that it can generate code snippets for a variety of languages, such as Python.
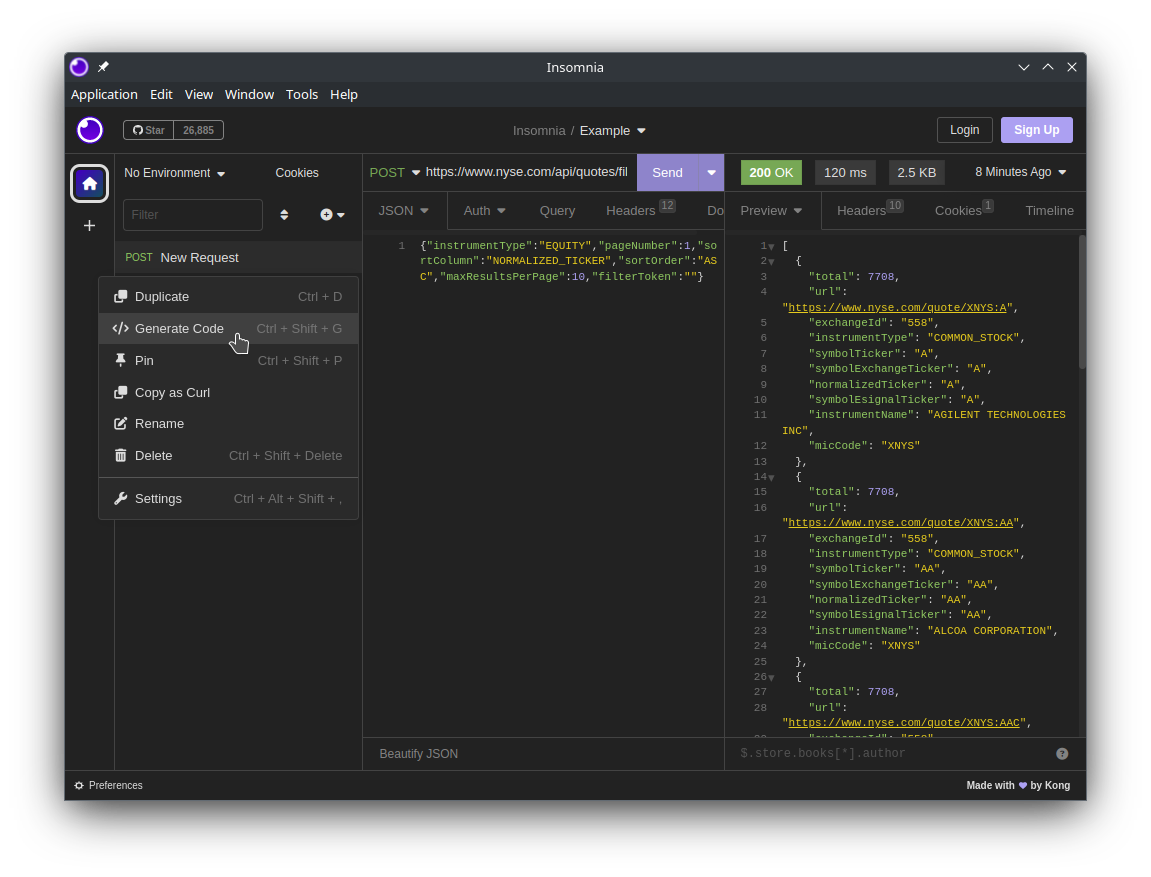
In that there are certain headers that are not strictly needed, such as cookies, typically these can be removed without any problem.
|
|
Putting it all Together
Now all that’s needed is to iterate over the pages, with the status code 500 representing the end condition.
|
|
Beyond that, multi-threading could be used speed up the the data fetching, but that’s another topic.